
LLMs are not the Path to AGI

A bold statement. Its validity hinges on the definition of ‘AGI’:
“A computer system that can learn incrementally, in real time, by itself, to reliably perform any cognitive task that a competent human can – including the discovery of new knowledge and solving novel problems.”
This description aligns with what we had in mind when we coined the term in 2002.
Real AGI will be able to teach itself any cognitive profession by ‘hitting the books’. It will be able to function as an effective researcher or scientist; as a manager, accountant, or assistant. It will be able to perform any cognitive, desk-bound job at human level competence or above. Importantly, it will be able to adapt to new information and changing circumstances on the fly.
AGI promises to usher in an era of radical abundance.
In order to achieve these lofty goals, an AGI system needs to embody a number of cognitive capabilities, including the ability to learn incrementally, in real-time, and to operate (largely) autonomously to acquire new skills and to execute them accurately.
It is now quite widely acknowledged that LLMs or Generative AI, and more generally, purely big data statistical models alone are not going to meet the requirements of AGI

Why?
Well, the name GPT already provides some clues:
Generative — They generate responses, make up stuff, from the trillions of bits of training data (Good, Bad, and Ugly) causing hallucinations and lack of reliability
Pretrained — These models are read-only at runtime. The model can only be updated via expensive, lengthy batch training ($100mil+ for GPT4)
Transformer — This core technology enabling their impressive performance relies on a form of backpropagation which inherently requires batch training
These features make LLMs inherently unreliable, non-adaptive, and expensive.
Importantly, this also implies that you always need a human-in-the-loop, both for validating responses (that they make sense) and for ongoing updates and development. In addition, ongoing human intelligence is also required to ‘engineer’ prompts.
Other headaches for Legal and Marketing are that LLMs are ‘black boxes’ — inscrutable, un-auditable, unexplainable, unsafe — and risk potential data-leaks and copyright infringements.
Is this fixable?
Hallucinations — Fine-tuning, parameter tweaking (e.g. temperature), data curation, and external validation (e.g. one LLM monitoring another) are some of the techniques used to improve accuracy. However, the system’s inability to tell good data from bad (or when it doesn’t actually know) and its lack of meta-cognition (analyzing its own processes) limits the degree of mitigation.
No Real-Time Learning — Two mechanisms attempting to overcome the lack of real-time learning ability are huge context windows and RAG (Retrieval Augmented Generation). Here are some of the issues with these approaches:
Data in the context window is not properly integrated or structured and therefore cannot be reliably retrieved or used. Large amounts of context are also slow and expensive to process
Indexing data, both for storage and retrieval, is still subject to the usual statistical inaccuracies and hallucinations
Neither approach actually updates the core model in a systematic or permanent manner
Black Box Opaqueness — Model analysis tools only provide very limited insight into the data structure, certainly not enough to make them explainable.
Expensive & Slow — Various hardware and software optimization techniques can mitigate these limitation, however, in an effort to make LLMs more useful, models and context windows are growing rapidly, likely offsetting such improvements.
Needs Human-in-the-loop — To make LLMs more trustworthy, significant effort goes into the design of application-specific external guardrails. Typically this ends up as a trade off between reliability and LLM usefulness.
By the time all of these mitigation measures plus others, like fine-tuning, are implemented it often seems like the tail is wagging the dog — i.e. how much are you actually getting out of the LLM versus all of the other, more traditional mechanisms. It should also be noted that ‘fine-tuning’ and partial retraining of models risks ‘catastrophic forgetting’ (wiki) where models suffer unpredictable performance regression.
Lack of Quality Data — Dearth of reliable training data is particularly acute for company specific, low volume, and specialized domain applications. There simply may not be enough data available to train the model, quite apart from the issue of high training cost for one-off use cases.
Automating workflow or procedures (Agentic AI) — Multi-step applications like for example customer support involve a series of actions such as obtaining information from a user, implementing contextual business rules, reading and updating APIs, and so on. Even an average accuracy of 95% per step quickly deteriorates to 66% after only 8 steps — clearly unacceptable for even moderately critical applications.
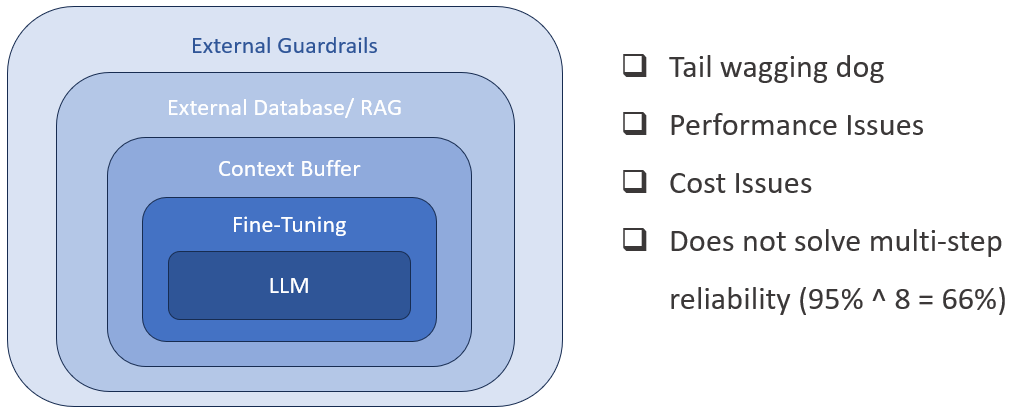
No, it does not seem to be fixable.
Given these difficulties, it makes sense to compare Generative AI to an alternative approach to AGI, namely Cognitive AI
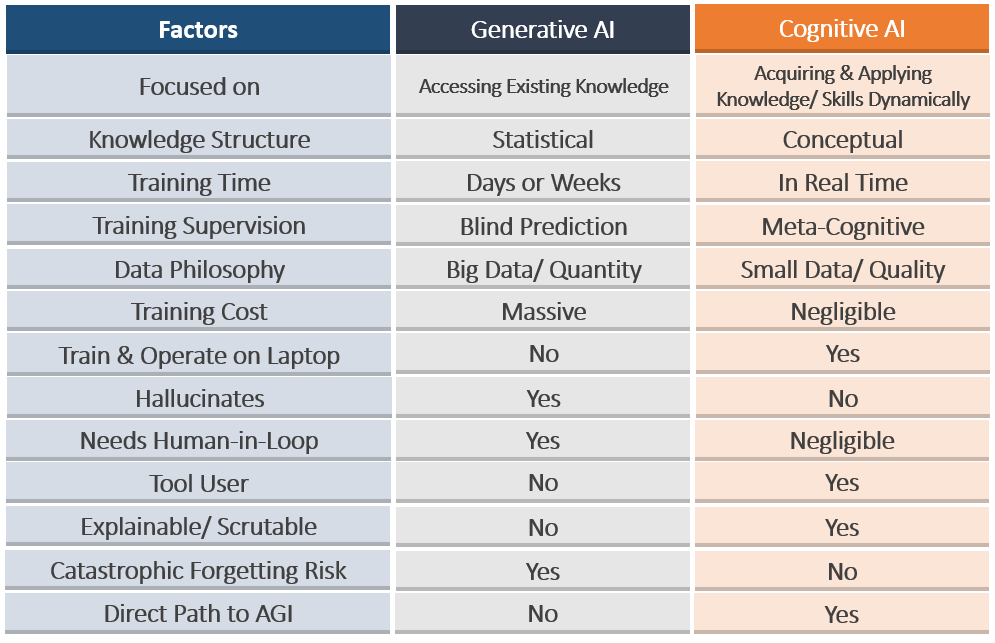
Indeed, if one focuses on core requirements of AGI such as incremental, conceptual, real-time learning plus high-level metacognitive reasoning it becomes clearer that LLMs are not on the path to AGI
Aigo’s INSA (Integrated Neuro-Symbolic Architecture) offers the direct path to AGI

.